Custom operators
ONNX Runtime provides options to run custom operators that are not official ONNX operators. Note that custom operators differ from contrib ops, which are selected unofficial ONNX operators that are built in directly to ORT.
Contents
- Define and register a custom operator
- Create a library of custom operators
- Calling a native operator from custom operator
- CUDA custom ops
- Wrapping an external inference runtime in a custom operator
Define and register a custom operator
A custom operator class inherits from Ort::CustomOpBase and provides implementations for member functions that define the operator’s characteristics and functionality. For example, the following snippet shows the class definition for a basic custom operator named “MyCustomOp” with 2 inputs and 1 output.
struct MyCustomOp : Ort::CustomOpBase<MyCustomOp, MyCustomKernel> {
void* CreateKernel(const OrtApi& api, const OrtKernelInfo* info) const {
return std::make_unique<MyCustomKernel>(api, info).release();
};
// Returns the name of the custom operator.
const char* GetName() const { return "MyCustomOp"; };
// Returns the custom operator's execution provider.
const char* GetExecutionProviderType() const { return "CPUExecutionProvider"; };
// Returns the number of inputs.
size_t GetInputTypeCount() const { return 2; };
// Returns the type of each input. Both inputs are tensor(float).
ONNXTensorElementDataType GetInputType(size_t index) const { return ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT; };
// Returns the number of outputs.
size_t GetOutputTypeCount() const { return 1; };
// Returns the type of each output. The single output is a tensor(float).
ONNXTensorElementDataType GetOutputType(size_t index) const { return ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT; };
};
Refer to the OrtCustomOp struct or the Ort::CustomOpBase struct definitions for a listing of all custom operator member functions.
A custom operator returns a custom kernel via its CreateKernel method. A kernel exposes a Compute method that is called during model inference to compute the operator’s outputs. For example, the following snippet shows the class definition for a basic custom kernel that adds two tensors.
struct MyCustomKernel {
MyCustomKernel(const OrtApi& api, const OrtKernelInfo* info) {}
void Compute(OrtKernelContext* context) {
// Setup inputs
Ort::KernelContext ctx(context);
Ort::ConstValue input_X = ctx.GetInput(0);
Ort::ConstValue input_Y = ctx.GetInput(1);
const float* X = input_X.GetTensorData<float>();
const float* Y = input_Y.GetTensorData<float>();
// Setup output, which is assumed to have the same dimensions as the inputs.
std::vector<int64_t> dimensions = input_X.GetTensorTypeAndShapeInfo().GetShape();
Ort::UnownedValue output = ctx.GetOutput(0, dimensions);
float* out = output.GetTensorMutableData<float>();
const size_t size = output.GetTensorTypeAndShapeInfo().GetElementCount();
// Do computation
for (size_t i = 0; i < size; i++) {
out[i] = X[i] + Y[i];
}
}
};
Refer to the API documentation for information on all available custom operator kernel APIs:
- C APIs for OrtKernelInfo and OrtKernelContext
- C++ APIs for Ort::KernelInfo
- C++ APIs for Ort::KernelContext
The following snippet shows how to use an Ort::CustomOpDomain to register a custom operator with an ONNX Runtime session.
const MyCustomOp my_custom_op;
Ort::Env env;
Ort::CustomOpDomain domain("my.customop.domain");
domain.Add(&my_custom_op); // Add a custom op instance to the domain.
Ort::SessionOptions session_options;
session_options.Add(domain); // Add the domain to the session options.
// Create a session.
Ort::Session session(env, ORT_TSTR("my_model_with_custom_ops.onnx"), session_options);
Create a library of custom operators
Custom operators can be defined in a separate shared library (e.g., a .dll on Windows or a .so on Linux). A custom operator library must export and implement a RegisterCustomOps function. The RegisterCustomOps function adds a Ort::CustomOpDomain containing the library’s custom operators to the provided session options.
The following code snippets show how to write a shared library with two custom operators. Refer to a complete example for more details.
// custom_op_library.h
#pragma once
#include <onnxruntime_c_api.h>
#ifdef __cplusplus
extern "C" {
#endif
ORT_EXPORT OrtStatus* ORT_API_CALL RegisterCustomOps(OrtSessionOptions* options, const OrtApiBase* api_base);
#ifdef __cplusplus
}
#endif
// custom_op_library.cc
#include "custom_op_library.h"
// Custom operator libraries are not typically linked with ONNX Runtime.
// Therefore, must define ORT_API_MANUAL_INIT before including onnxruntime_cxx_api.h
// to indicate that the OrtApi object will be initialized manually.
#define ORT_API_MANUAL_INIT
#include "onnxruntime_cxx_api.h"
#undef ORT_API_MANUAL_INIT
#include <vector>
#include <cmath>
#include <mutex>
// Define custom operators and kernels ...
struct MyCustomOp : Ort::CustomOpBase<MyCustomOp, MyCustomKernel> {
// ...
};
struct MyOtherCustomOp : Ort::CustomOpBase<MyOtherCustomOp, MyOtherCustomKernel> {
// ...
};
// This function shows one way of keeping domains alive until the library is unloaded.
static void AddOrtCustomOpDomainToContainer(Ort::CustomOpDomain&& domain) {
static std::vector<Ort::CustomOpDomain> ort_custom_op_domain_container;
static std::mutex ort_custom_op_domain_mutex;
std::lock_guard<std::mutex> lock(ort_custom_op_domain_mutex);
ort_custom_op_domain_container.push_back(std::move(domain));
}
// Called by ONNX Runtime to register the library's custom operators with the provided session options.
OrtStatus* ORT_API_CALL RegisterCustomOps(OrtSessionOptions* options, const OrtApiBase* api) {
Ort::InitApi(api->GetApi(ORT_API_VERSION)); // Manually initialize the OrtApi to enable use of C++ API classes and functions.
// Custom operators are static to ensure they remain valid until the library is unloaded.
static const MyCustomOp my_custom_op;
static const MyOtherCustomOp my_other_custom_op;
OrtStatus* result = nullptr;
try {
Ort::CustomOpDomain domain{c_OpDomain};
domain.Add(&c_CustomOpOne);
domain.Add(&c_CustomOpTwo);
Ort::UnownedSessionOptions session_options(options);
session_options.Add(domain);
AddOrtCustomOpDomainToContainer(std::move(domain));
} catch (const std::exception& e) {
Ort::Status status{e};
result = status.release();
}
return result;
}
Once compiled, the custom operator shared library can then be registered with an ONNX Runtime session.
Ort::Env env;
Ort::SessionOptions session_options;
session_options.RegisterCustomOpsLibrary_V2(ORT_TSTR("my_custom_op.dll"));
Ort::Session session(env, ORT_TSTR("my_model.onnx"), session_options);
Examples
-
C++ helper API: custom ops
MyCustomOpandSliceCustomOpuse the C++ helper API. The test file also demonstrates an option to compile the custom ops into a shared library to be used to run a model via the C++ API. -
Custom op shared library: sample custom op shared library containing two custom kernels.
-
Custom op shared library with Python API:
testRegisterCustomOpsLibraryuses the Python API to register a shared library with custom op kernels. Currently, the only supported Execution Providers (EPs) for custom ops registered via this approach are CUDA and CPU. -
E2E example: Export PyTorch model with custom ONNX operators.
-
Using Custom Ops with TF2ONNX: This notebook covers converting a TF model using an existing custom op, defining new custom ops in Python to use in conversion, and defining new custom ops in C++.
Calling a native operator from custom operator
To simplify implementation of custom operators, native onnxruntime operators can directly be invoked. For example, some custom ops might have to do GEMM or TopK in between other computations. This may also be useful for preprocessing and postprocessing on a node, such as Conv, for state management purpose. To achieve this, the Conv node can be wrapped up by a custom operator such as CustomConv, within which the input and output could be cached and processed.
This feature is supported from ONNX Runtime 1.12.0+. See: API and examples.
CUDA custom ops
When a model is run on a GPU, ONNX Runtime will insert a MemcpyToHost op before a CPU custom op and append a MemcpyFromHost after it to make sure tensors are accessible throughout calling.
When using CUDA custom ops, to ensure synchronization between ORT’s CUDA kernels and the custom CUDA kernels, they must all use the same CUDA compute stream. To ensure this, you may first create a CUDA stream and pass it to the underlying Session via SessionOptions (use the OrtCudaProviderOptions struct). This will ensure ORT’s CUDA kernels use that stream and if the custom CUDA kernels are launched using the same stream, synchronization is now taken care of implicitly.
For example, see how the afore-mentioned MyCustomOp is being launched and how the Session using this custom op is created.
Wrapping an external inference runtime in a custom operator
A custom operator can wrap an entire model that is then inferenced with an external API or runtime. This can facilitate the integration of external inference engines or APIs with ONNX Runtime.
As an example, consider the following ONNX model with a custom operator named “OpenVINO_Wrapper”. The “OpenVINO_Wrapper” node encapsulates an entire MNIST model in OpenVINO’s native model format (XML and BIN data). The model data is serialized into the node’s attributes and later retrieved by the custom operator’s kernel to build an in-memory representation of the model and run inference with OpenVINO C++ APIs.
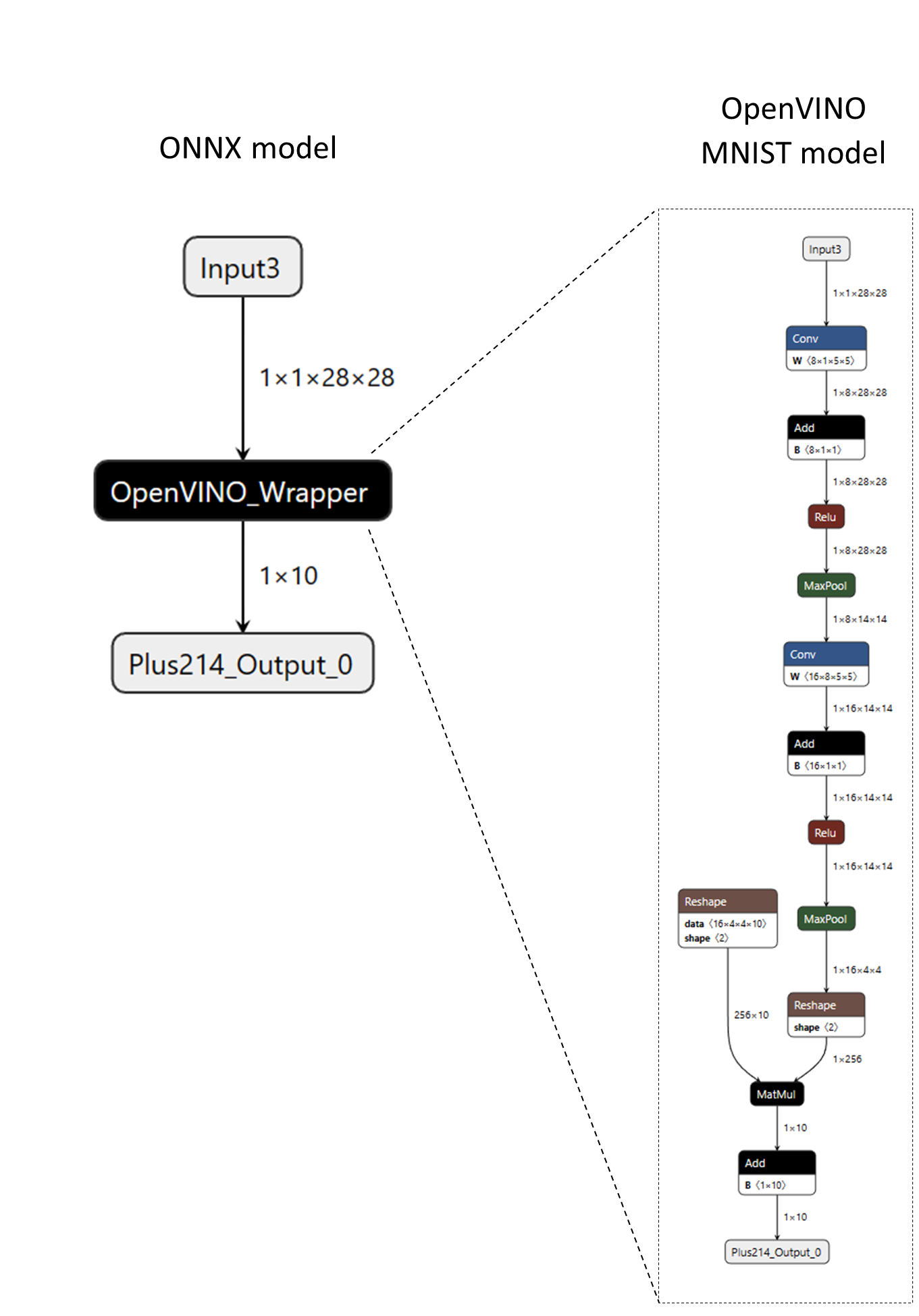
The following code snippet shows how the custom operator is defined.
struct CustomOpOpenVINO : Ort::CustomOpBase<CustomOpOpenVINO, KernelOpenVINO> {
explicit CustomOpOpenVINO(Ort::ConstSessionOptions session_options);
CustomOpOpenVINO(const CustomOpOpenVINO&) = delete;
CustomOpOpenVINO& operator=(const CustomOpOpenVINO&) = delete;
void* CreateKernel(const OrtApi& api, const OrtKernelInfo* info) const;
constexpr const char* GetName() const noexcept {
return "OpenVINO_Wrapper";
}
constexpr const char* GetExecutionProviderType() const noexcept {
return "CPUExecutionProvider";
}
// IMPORTANT: In order to wrap a generic runtime-specific model, the custom operator
// must have a single non-homogeneous variadic input and output.
constexpr size_t GetInputTypeCount() const noexcept {
return 1;
}
constexpr size_t GetOutputTypeCount() const noexcept {
return 1;
}
constexpr ONNXTensorElementDataType GetInputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr ONNXTensorElementDataType GetOutputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr OrtCustomOpInputOutputCharacteristic GetInputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr OrtCustomOpInputOutputCharacteristic GetOutputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr bool GetVariadicInputHomogeneity() const noexcept {
return false; // heterogenous
}
constexpr bool GetVariadicOutputHomogeneity() const noexcept {
return false; // heterogeneous
}
// The "device_type" is configurable at the session level.
std::vector<std::string> GetSessionConfigKeys() const { return {"device_type"}; }
private:
std::unordered_map<std::string, std::string> session_configs_;
};
Note that the custom operator is defined to have a single variadic/heterogenous input and a single variadic/heterogeneous output. This is necessary to enable wrapping OpenVINO models with varying input and output types and shapes (not just an MNIST model). For more information on input and output characteristics, refer to the OrtCustomOp struct documentation.
Additionally, the custom operator declares “device_type” as a session configuration that can be set by the application. The following code snippet shows how to register and configure a custom operator library containing the aforementioned custom operator.
Ort::Env env;
Ort::SessionOptions session_options;
Ort::CustomOpConfigs custom_op_configs;
// Create local session config entries for the custom op.
custom_op_configs.AddConfig("OpenVINO_Wrapper", "device_type", "CPU");
// Register custom op library and pass in the custom op configs (optional).
session_options.RegisterCustomOpsLibrary("MyOpenVINOWrapper_Lib.so", custom_op_configs);
Ort::Session session(env, ORT_TSTR("custom_op_mnist_ov_wrapper.onnx"), session_options);
Refer to the complete OpenVINO custom operator wrapper example for more details. To create an ONNX model that wraps an external model or weights, refer to the create_custom_op_wrapper.py tool.