Attention
This version of the SDK has been superseded by the latest release of the SDK.
Specs and Features of the AMD AMA Video SDK¶
The AMD AMA Video SDK¶
The AMD AMA Video SDK is a complete software stack allowing users to seamlessly leverage the features of AMD video acceleration units such as MA35D. It includes the following elements:
Pre-compiled versions of FFmpeg and GStreamer which integrate key video transcoding plug-ins, enabling simple hardware offloading of compute-intensive workloads using these two popular frameworks. These custom versions of FFmpeg and GStreamer link to a host driver which communicates with the hardware on the PCIe card. No hardware experience is required to run FFmpeg or GStreamer commands with the AMD AMA Video SDK.
The Xilinx Resource Manager (XRM) which is the software used to manage and allocate all the hardware-accelerated features available in the system. XRM allows running multiple video processing jobs across multiple devices and multiple AMD video acceleration cards.
A C-based application programming interface (API) which facilitates the integration of AMD video transcoding capabilities in proprietary frameworks. This API is provided in the form plugins which can be called from external application using the Xilinx Media Accelerator (XMA) interface.
A suite of card management tools used to perform actions such as programming, resetting, or querying the status of AMD video acceleration cards.
Many examples and tutorials illustrating how to use and make the most of the AMD AMA Video SDK.
The AMD MA35D Card¶
The MA35D, which is compatible with AMD AMA Video SDK, is a low-profile, PCI™-based media accelerator card that delivers a high-density real-time transcoding solution for live streaming video service providers, OEMs, and Content Delivery Network (CDNs).
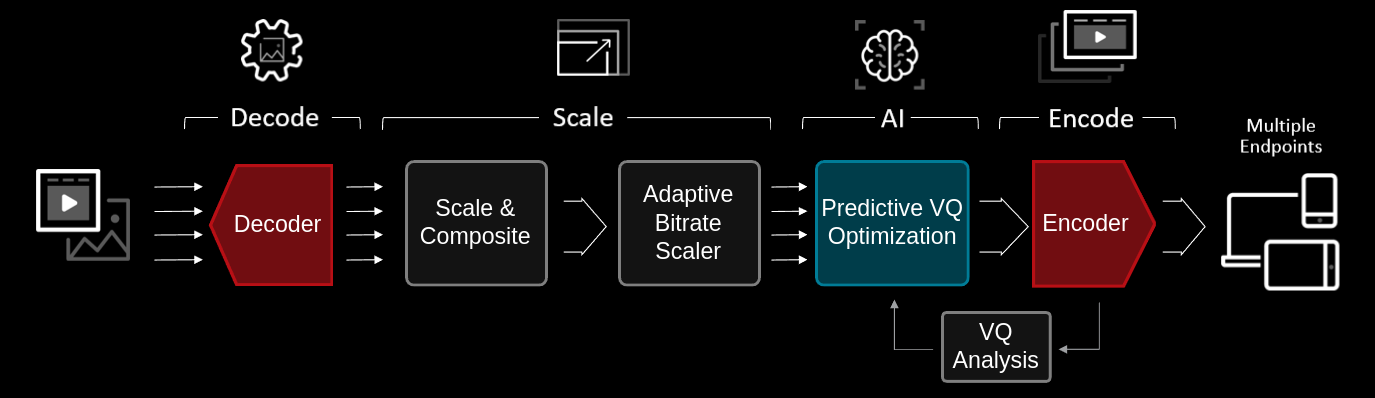
The MA35D card is targeted for both real-time and faster than real-time video workloads. It is expected that one or more sources of video input, either from files or from live video streams, are fed into the transcode pipeline. The encoder encodes one or more output streams from each scaled rendition of the input.
Video Codec Unit¶
The MA35D accelerator card has 2 VPUs, where each VPU is made of 2 video processing slices.
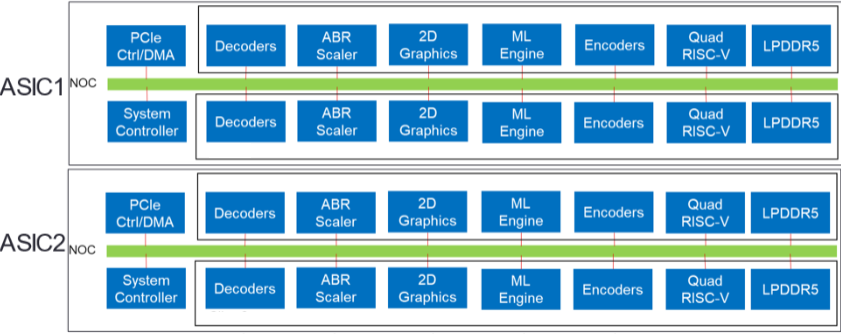
Functionally, slices are made of specialized decode, scale, GPU, ML, look ahead, pixel processing, and encode units.
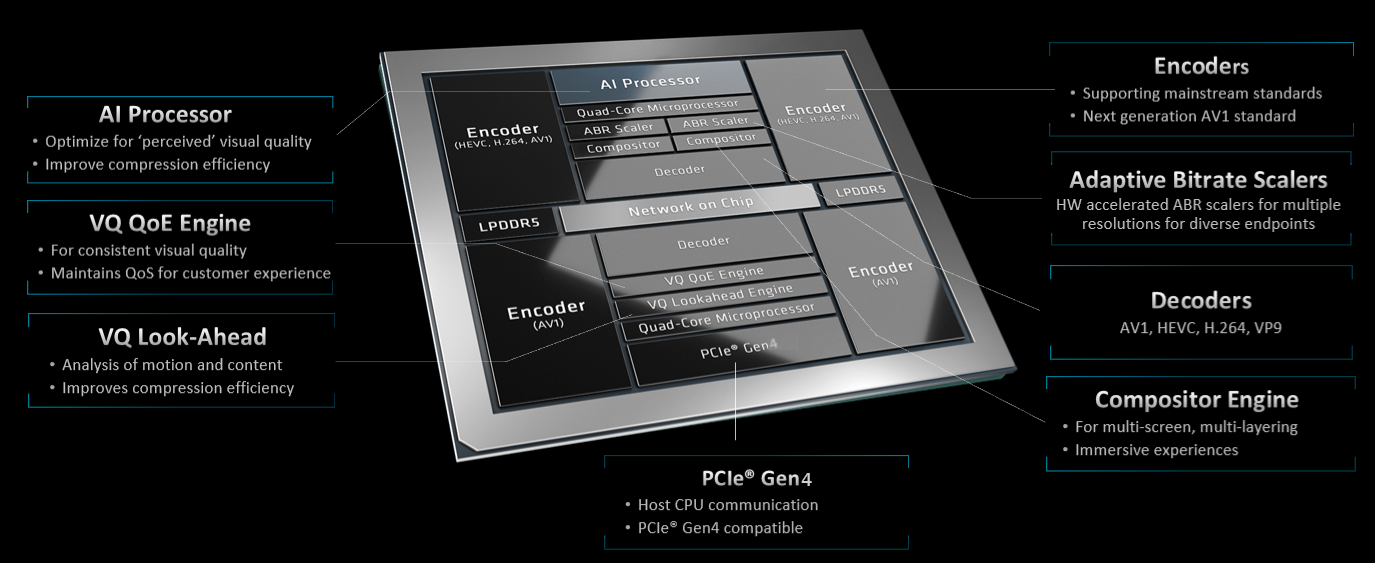
Video Codec Unit (VCU) cores are capable of:
Video format: YCbCr 4:2:0, 8 or 10-bit per color channel
Multi-standard encoding/decoding support, including:
ISO MPEG-4 Part 10: Advanced Video Coding (AVC)/ITU H.264 - Baseline, Main, High, High-10, High-10-Intra up to Level 6.2
ISO MPEG-H Part 2: High Efficiency Video Coding (HEVC)/ITU H.265 - Main, Main-Intra, Main10, Main-10-Intra, up to Level 6.2
AOM AV1: AOMedia Video 1 - High up to Level 6.3
VP9 Decoding: Profiles 0 and 1, for 8 and 10 bits contents
JPEG Encoding: Baseline interleaved and Lossless
JPEG Decoding: Baseline interleaved and Progressive
Supports encode resolutions from 144x144 to 3840x2160, for H.264, H.265 and AV1 Type 2, and up to 7680x4320, for AV1 Type 1 and JPEG, in both portrait and landscape modes
Supports decode resolutions from 144x144 to 7680x4320, for all video codecs, and 48x48 to 7680x4320, for JPEG, in both portrait and landscape modes
Simultaneous transcoding with a maximum aggregated bandwidth of 4x 4Kp60 per card for AVC or HEVC and 8x 4Kp60 for AV1
Look-ahead driven video quality improvements through temporal adaptive and spatial adaptive quantization
Low latency rate control
Flexible rate control: CBR, VBR, CVBR, and Constant QP
Progressive support for H.264, H.265 and AV1
HDR10/10+: HDR data is automatically populated by the decoder and passed to other accelerators in the transcode pipeline.
The following HDR10 SEI are supported:
Mastering Display Color Volume (SEI ITU)
Content Light Level (SEI ITU)
Alternative Transfer Charateristics (SEI ITU)
The following HDR10+ SEI are supported:
ST2094_10 (DolbyVision, User defined SEI)
ST2094_40 (Samsung, User defined SEI)
Behavior for HDR10/10+ SEI is as follows:
Static HDR SEI (MDCV, CLL & ATC) will not change in-between IDRs (and even in the video sequence according the HDR standards).
MDCV, CLL & ATC will be written only on IDRs, according to the persistency of MDCV, CLL & ATC SEIs.
ST2094_10 will be written on each access unit as per constraint of section A.2.1 ts_103572v010101p.pdf.
ST2094_40 will be written on IDRs, and whenever the user changes its content, according to the persistency specification in A341S34-1-582r4-A341-Amendment-2094-40.pdf
Adaptive Bitrate Scaler¶
For streaming applications, video is distributed in different resolutions and bit rates to adapt to varying network bandwidth conditions. All adaptive bitrate (ABR) transcoding systems require an ABR scaler that downscales an input video stream to several different smaller resolutions that are then re-encoded. These smaller resolutions are referred to as an image pyramid or an ABR ladder.
The MA35D ABR scaler is an accelerator capable of generating up to 16 lower resolution output images from a single input image. The ABR scaler supports the following features:
Supports up to 12 taps in both horizontal and vertical direction per stage
High quality polyphase scaling with 64 phases and up to 12 taps in both horizontal and vertical direction per stage
Supports 8 and 10-bit 4:2:0
Luma and Chroma processed in parallel
Supports resolutions from 128x128 to 3840x2160, in multiples of 4
The scaler is tuned for downscaling and expects non-increasing resolutions in an ABR ladder. Increasing resolutions between outputs is supported but will reduce video quality.
Note
The MA35D ABR scaler is tuned for downscale ratios of up to 3, e.g., from 2160p to 1080p or 720p. For larger ratios, it is recommended to generate intermediary scales, of ratios below 3.
As an example, the following FFmpeg command downscales a HEVC 4k content to 540p, by creating an intermediary step, where input is initially scaled from 4k to 1080p:
ffmpeg -hwaccel ama -hwaccel_device /dev/ama_transcoder0 -c:v hevc_ama -i <4K INPUT> -filter_complex "[0:v]scaler_ama=outputs=2:out_res=(1920x1080|full)(960x540|full)[n][f]" -map '[f]' -c:v h264_ama -y -f mp4 <540 OUTPUT> -map '[n]' -f null /dev/null
Decoder Downsampler¶
Along with the above dedicated ABR scaler, MA35D's decoder also offers downsampling capabilities, e.g., see -resize. Given that the latter is part the decoding engine, unlike the ABR scaler, there are no bandwidth penalties associated with this downsampler. As such, it's usage is recommended for high throughput use cases, e.g., transcoding 8x4kp60 to 8x1440p60, in single density mode.
2D Pixel Processing¶
MA35D offers a rich collection of accelerated 2D pixel processing. These include:
Cropping
Padding
Box drawing
Rotate
Color space conversion
Chroma subsampling
Blend
Overlay
Tiling
As an example, see 2D Engine for how to use these filters in FFmpeg. Note that the input resolution, to these filters, must be divisible by 4.
Decoding Capacity¶
Each decoder in a MA35D card, where 4 exist per card, is made out of 2 engines. Cores 0 and 1 delineate one engine; whereas, cores 2 and 3 the other. Each engine is capable of 8 and 10 bit 4x4kp60 aggregated throughput. Both engines support AVC, HEVC and VP9 decoding; however, only cores 0 and 1 support AV1 decoding. It is noted that load balancing between the engines is done in a transparent manner and does not require user intervention.
As an example, the following command shows a fully loaded decoder, on device 1, where cores 0 and 1 are decoding 16 AV1 streams, while cores 2 and 3 are decoding 16 AVC streams:
for i in `seq 1 16`; do \
ffmpeg -nostdin -hide_banner -loglevel fatal -hwaccel ama -hwaccel_device /dev/ama_transcoder0 -re -c:v av1_ama -i av1_1080p60.mp4 -f null /dev/null & \
ffmpeg -nostdin -hide_banner -loglevel fatal -hwaccel ama -hwaccel_device /dev/ama_transcoder0 -re -c:v h264_ama -i h264_1080p60.mp4 -f null /dev/null & \
done
The accompanying mautil examine -d all -r utilization shows:
===================================================================================================
1/4 [01:00.0] : MA35 Device
---------------------------------------------------------------------------------------------------
Accelerator Utilization Info [01:00.0]
---------------------------------------------------------------------------------------------------
Accelerator Average Core-0 Core-1 Core-2 Core-3
(%) (%) (%) (%) (%)
-------------------------- --------- --------- --------- --------- ---------
Decoder : 100 100 100 100 100
Scaler : 0 0 0 -- --
Encoder Type-1 : 0 0 0 -- --
Encoder Type-2 : 0 0 0 -- --
2D GPU : 0 0 0 -- --
ML NPU : 0 0 0 0 0
To demonstrate the auto load balancing feature, the following command shows decoding of 32 AVC streams:
for i in `seq 1 32`; do \
ffmpeg -nostdin -hide_banner -loglevel fatal -hwaccel ama -hwaccel_device /dev/ama_transcoder0 -re -c:v h264_ama -i h264_1080p60.mp4 -f null /dev/null & \
done
The accompanying mautil examine -d all -r utilization shows:
===================================================================================================
1/4 [01:00.0] : MA35 Device
---------------------------------------------------------------------------------------------------
Accelerator Utilization Info [01:00.0]
---------------------------------------------------------------------------------------------------
Accelerator Average Core-0 Core-1 Core-2 Core-3
(%) (%) (%) (%) (%)
-------------------------- --------- --------- --------- --------- ---------
Decoder : 100 100 100 100 100
Scaler : 0 0 0 -- --
Encoder Type-1 : 0 0 0 -- --
Encoder Type-2 : 0 0 0 -- --
2D GPU : 0 0 0 -- --
ML NPU : 0 0 0 0 0
Note that once again decoding engines, on device 1, are fully utilized; however, this time, all the cores are performing AVC decoding.
Video Quality¶
The MA35D card nominally produces video quality (VQ) that is closely correlated to x264 medium, x265 medium and x265 slow presets, with respect to its accelerated AVC, HEVC and AV1 encoders. Furthermore, in case of AV1 encoders, -type-1 AV1 matches a similar VQ as x265 slow; whereas, -type-2 that of x265 medium. This video quality is highly dependent on video content so actual results may vary.
Machine Learning Engine¶
The ML engine in each device is capable of supporting a wide range of vision and AI related tasks. Each engine has built in hardware accelerated instruction sets, which support tensor processing, hardware tiling, and enhanced vision processing. With 11 TOPs processing throughput, per device, MA35D is capable of performing state of art ML encoding as demonstrated in ROI Encoding and in Machine Learning Content Aware Encoding.
Pixel Format¶
While AMA accelerator engines support various pixel formats; however, Interchange Formats (IF s) are the most suitable ones for in-between engine communication, as they offer the smallest memory footprint and the highest throughput. The following table lists the supported pixel formats, including IF ones:
Engine Name |
8-Bit |
10-Bit |
Notes |
|---|---|---|---|
Decoder |
p010le, i.e., P010_10LE is not supported in Gstreamer.
|
||
Scaler |
|||
Encoder |
JPEG encode does not support 10 bit format
Lossless JPEG encode does not support nv12-tile pixel format.
|
||
DMA |
nv12
yuv420p
bgr0
bgra
argb
rgbp
uyv422
|
packed10
p010le
yuv420p10le
|
|
2D Engine |
yuv420p10le does not support 90/270 rotation
rgbp is supported only at the output
422, rgba, and abgr formats are not supported in FFmpeg
|
, where tiles are 4x4 pixels.
Performance Tables¶
The video processing power of the MA35D cards can be harnessed in many different ways, from running a few high-definition jobs to running many low-resolution ones, with or without scaling. The tables below show how many jobs can be run at real-time speed based on the use case and the number of cards available. All these configurations have been tested and validated by AMD and assume normal operating ranges.
Note
In the following tables, density numbers linearly scale to up to 16 devices.
It is assumed that per device, host chassis has set aside 8 hyper-threaded cores with 12GB of RAM.
Note
To meet the following density numbers for 30 FPS pipelines or VP9 decoding, it is recommended to decrease LA depth incrementally, until target density objectives are met. Refer to Automatic Look Ahead Depth Calculation for valid range of LA depth.
The following tables present density numbers for typical video renditions. However, it should be noted that encode capability of each engine, 4 per device, is best described as aggregated 4kp60. This, among other things, implies that densities of 4x1080p60 or rate of 1x1080p240 can be achieved. The latter implies that a 1080p60 VOD asset can be encoded at 4 times the speed. Furthermore, speed up rate holds linearly for renditions down to 540p30. To encode two Faster Than Real Time (FTRT) jobs on a single device, each job must be assigned to a dedicated slice. See -slice for details.
In tables, below, Single Density refers to any combination of AVC, HEVC or AV1 Type-2 encoders, whereas, Double Density refers to any combination of AVC, HEVC or AV1 Type-2 encoders along with AV1 Type-1 encoder.
It is noted that with respect to Transcode with Scale Jobs Tables, below, the output of a decoder can be split and encoded with any combination of AMA encoders. This in turn implies that the expected density numbers can vary from reported Single Density to Double Density, depending on encoder selection, for each output of the scaler.
To fully utilize all devices on a card and reach the stated densities, device selection needs to be explicitly done in a command line. See -hwaccel and Using Explicit Device IDs for more details. Refer to Full Double Density for an example on how to deploy double density pipelines.
Performance Tables for 8-bit Color¶
Transcode Use Case |
Single Density |
Single Density |
Double Density |
|---|---|---|---|
4kp75 (See |
4 |
0 |
0 |
4kp60 |
4 |
4 |
8 |
4kp30 |
8 |
8 |
16 |
1080p60 |
20 |
16 |
32 |
1080p30 |
40 |
32 |
64 |
720p60 |
40 |
32 |
64 |
720p30 |
84 |
68 |
136 |
Transcode with Scale Use Case |
Single Density |
Double Density |
|---|---|---|
4kp60 to 1440p60 |
4 |
8 |
4kp30 to 1440p30 |
8 |
16 |
1080p60 to 720p60 |
16 |
32 |
1080p30 to 720p30 |
32 |
64 |
720p60 to 540p60 |
32 |
64 |
720p30 to 540p30 |
68 |
136 |
ABR Ladders Use Case |
1 Card |
|---|---|
2160p60 to 1440p60, 1080p60, 720p30, 480p30, 360p30, 240p30, 144p30 |
4 |
2160p30 to 2160p30, 1440p30, 1080p30, 720p30, 480p30, 360p30, 240p30, 144p30 |
4 |
1080p60 to 1080p60, 720p60, 720p30, 480p30, 360p30, 160p30 |
8 |
1080p60 to 720p60, 720p30, 480p30, 360p30, 160p30 |
16 |
1080p30 to 1080p30, 720p30, 480p30, 240p30 |
16 |
720p30 to 720p30, 480p30, 240p30 |
40 |
Performance Tables for 10-bit Color¶
Transcode Use Case |
Single Density |
Single Density |
Double Density |
|---|---|---|---|
4kp75 (See |
4 |
0 |
0 |
4kp60 |
4 |
4 |
8 |
4kp30 |
8 |
8 |
16 |
1080p60 |
20 |
16 |
32 |
1080p30 |
40 |
32 |
64 |
720p60 |
40 |
32 |
64 |
720p30 |
84 |
68 |
136 |
Transcode with Scale Use Case |
Single Density |
Double Density |
|---|---|---|
4kp60 to 1440p60 |
4 |
8 |
4kp30 to 1440p30 |
8 |
16 |
1080p60 to 720p60 |
16 |
32 |
1080p30 to 720p30 |
32 |
64 |
720p60 to 540p60 |
32 |
64 |
720p30 to 540p30 |
68 |
136 |
ABR Ladders Use Case |
1 Card |
|---|---|
2160p60 to 1440p60, 1080p60, 720p30, 480p30, 360p30, 240p30, 144p30 |
4 |
2160p30 to 2160p30, 1440p30, 1080p30, 720p30, 480p30, 360p30, 240p30, 144p30 |
4 |
1080p60 to 1080p60, 720p60, 720p30, 480p30, 360p30, 160p30 |
8 |
1080p60 to 720p60, 720p30, 480p30, 360p30, 160p30 |
16 |
1080p30 to 1080p30, 720p30, 480p30, 240p30 |
16 |
720p30 to 720p30, 480p30, 240p30 |
40 |